在 Golang 中尝试干净架构
架构是一个哲学问题,并且复杂,我也才跨入了一根脚指头,如有不正,感谢指教。
什么是“干净架构” ?

“干净架构”是 Robert C. Martin (Uncle Bob)(About,Robert C·Martin Robert C·Martin的作品(16))在 2012 年总结现有的系统架构并提出的一个理念。
在文中,他提出的干净架构是这样的:
- 独立于框架。该体系结构不依赖于某些功能丰富的软件库的存在。这允许您使用各种各样的框架作为工具。
- 可测试的。业务规则可以在没有 UI、数据库、Web 服务器或任何其他外部元素(如第三方RPC服务)的情况下进行测试。
- 独立于用户界面。用户界面可以很容易地更改,而不必更改系统的其他部分。例如,Web 用户界面可以替换为控制台界面,而不必更改业务规则。
- 独立于数据库。您可以将 Oracle 或 SQL Server 换成 Mongo, BigTable, CouchDB 或其他东西。您的业务规则未绑定到数据库。
- 独立于任何外部机构(下图中的外层)。实际上,您的业务规则根本不了解外部世界。
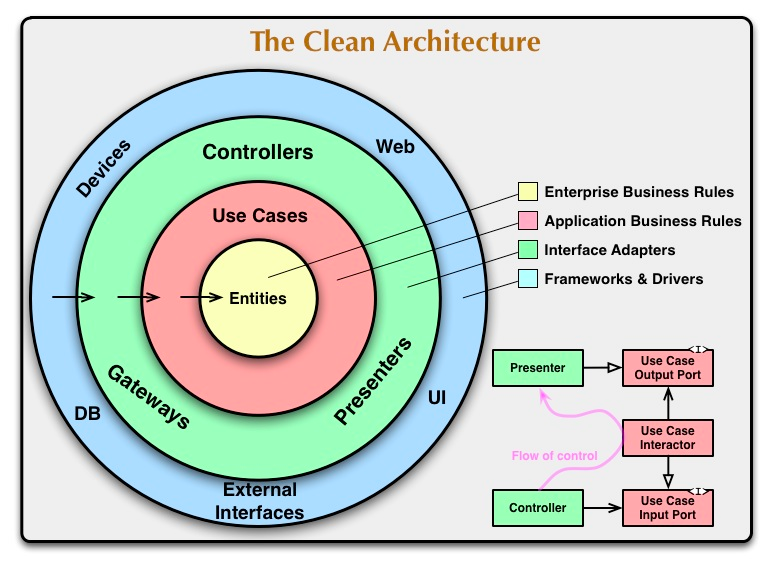
图中的总体思想是依赖的方向只能是从外向内。也就是说,外部的圈依赖内部的圈,内部的圈不能依赖外部。外层中命名和数据格式不能影响内层。
“干净架构”在 Golang 中如何落地?
由于每种语言的特性与包组织方式有些许不同,所以只看思想指导就想要在 Golang 中落地会有些困难,不过幸运的是,也有人在探索同样的事:
在 Uncle Bob 的干净架构中,有 4 层模型,同样这篇文章的作者也提出 4 层架构来实现干净架构的特点,即:Model,Repository,Usecase,Delivery。
基础概念
Model 模型层
Model 层存放所有的对象以及它们的方法,所有层都可能会用到。
Repository 存储库层
Repository 将存放任何数据库处理逻辑。该层将仅用于 CRUD 操作数据库,一般情况下没有业务逻辑发生。
该层还负责选择在应用程序中使用的数据库,比如 Mysql、MongoDB、Postgresql。
如果调用微服务也会在这里处理。
此存储库层将依赖于 DB 或其他微服务。
Usecase 用例层
和目前项目中的 Service 层概念一样。该层将编写业务逻辑代码。该层将决定使用哪个存储库层。并有责任提供数据以供 Delivery 层使用。处理数据做计算或在这里做任何事情。
此用例层依赖于存储库层
Delivery 分发层
该层将充当演示者。决定数据的呈现方式。可以是 REST API、HTML 文件或 GRPC,无论交付类型如何。 该层也将处理来自用户的输入并将其发送到用例层。
该层将依赖于用例层。
层间通信
除了模型之外,每一层都将通过接口进行通信。
比如Usecase层需要Repository层,Repository 将提供一个接口作为他们的合约和通信方式。
package repository
import models "github.com/bxcodec/go-clean-arch/article"
type ArticleRepository interface {
Fetch(cursor string, num int64) ([]*models.Article, error)
GetByID(id int64) (*models.Article, error)
GetByTitle(title string) (*models.Article, error)
Update(article *models.Article) (*models.Article, error)
Store(a *models.Article) (int64, error)
Delete(id int64) (bool, error)
}
Delivery 层也需要与 Usecase 层通信,Usecase 层也会提供一个接口作为他们的合约和通信方式。
package usecase
import (
"github.com/bxcodec/go-clean-arch/article"
)
type ArticleUsecase interface {
Fetch(cursor string, num int64) ([]*article.Article, string, error)
GetByID(id int64) (*article.Article, error)
Update(ar *article.Article) (*article.Article, error)
GetByTitle(title string) (*article.Article, error)
Store(*article.Article) (*article.Article, error)
Delete(id int64) (bool, error)
}
测试每一层
- Model:这一层最为最基础的数据结构层,不依赖任何服务所以很方便就能测试。
- Repository:由于依赖了数据库,最好的测试方法是在本地运行一个数据库服务来进行测试。当然也可以使用一些包来 Mock 数据库,如 github.com/DATA-DOG/go-sqlmock。
- Usecase:这一层的测试代码需要得最多,因为这一层会编写很多业务逻辑,它依赖 Repository 层的 Interface,要 Mock Interface 极为简单,所以也很方便的就能构建出 Usecase 来进行测试。
- Delivery:这一层大多是适配代码(如处理入参和出参),不会有太多问题,一般情况下可以不写测试用例,但如果要写,和测试 Usecase 层一样,Delivery 依赖的也是 Interface,故很好构建与测试。
提示:
如果 Repository 或 Usecase 依赖缓存,记得也将 Cache 声明为 Interface,代码不多,但让单元测试容易很多。
type Cacher interface {
Get(key string) (value string, exist bool, err error)
Set(key string, value string, expire int) error
Del(key string) error
}
合并每一层并运行
package main
import (
"database/sql"
"fmt"
"net/url"
httpDeliver "github.com/bxcodec/go-clean-arch/article/delivery/http"
articleRepo "github.com/bxcodec/go-clean-arch/article/repository/mysql"
articleUcase "github.com/bxcodec/go-clean-arch/article/usecase"
cfg "github.com/bxcodec/go-clean-arch/config/env"
"github.com/bxcodec/go-clean-arch/config/middleware"
_ "github.com/go-sql-driver/mysql"
"github.com/labstack/echo"
)
func main() {
dsn := config.GetString(`database`)
dbConn, err := sql.Open(`mysql`, dsn)
defer dbConn.Close()
e := echo.New()
ar := articleRepo.NewMysqlArticleRepository(dbConn)
au := articleUcase.NewArticleUsecase(ar)
httpDeliver.NewArticleHttpHandler(e, au)
e.Start(config.GetString("server.address"))
}
理想与现实 - 取消非必要的 Interface
当我们真正要将上面的理论落地的时候,会发现它太过理想,分层 + Interface 写起来很费劲费时。
为了优化,我们可以适当减少 Interface,不那么干净,却更实用,团队也更容易接受。
使用 Interface 的好处有下:
- 与依赖解耦,方便测试。
- 与依赖解耦,方便替换实现。
为了减少 Interface 而不影响测试与替换实现,我们应该提前预判哪一部分逻辑是依赖复杂的。
例 A,我们在项目中依赖一个 Http 服务,为了我们能在断网时也能测试代码,我们需要 Mock 这个 Http 服务,即需要 Interface 化这个服务。
例 B,我们在项目中依赖 Mysql 做存储,按理说我们也应该将代码 Interface 化,但,我们 99% 的情况下做测试就应该和 Mysql 一起测试,99% 的情况不会再使用其他实现(如换成 RPC、PGSQL),所以权衡后,我们为了方便,就没必要做 Interface 化。
同时 例 A 的依赖在一个项目中是少数的,例 B 的依赖是多数的,将少数依赖 Interface 化更好落地。
如果这个依赖是第三方的,自己不可控,则最好 Interface 化,这样可以 Mock 这个依赖,避免这个依赖的问题导致你的进度阻塞。
更多细节
错误处理
我们需要解决在多层架构下的区分“业务错误”与“系统错误”,不误报错误。
我们可以从几个方面来优化 Error 来方便使用:
- Wrap 更多信息
- 打印代码行数
- 传递 / 修改 Code 码
“装饰器模式”能做什么?
先看一段 Python 代码
import time
def timeit(func):
def wrapper():
start = time.clock()
func()
end =time.clock()
print 'used:', end - start
return wrapper
@timeit
def foo():
print 'in foo()'
foo()
只需要在 foo 方法上添加 @timeit 即可打印出函数执行时间。
可以看到,它可以在不改变原来代码的情况下,给一个方法添加一些功能,这些功能包括:
- 缓存
- 事务
- 认证、权限判断
- Log、Tracing、Measure
- ...
示例
缓存
https://github.com/bxcodec/go-clean-arch/issues/11#issuecomment-594679205
权限判断
type BookUsecase interface {
DeleteById(id int64) error
}
type BookUsecaseWithPermission struct {
BookUsecase
permission Permissioner
}
func (u BookUsecaseWithPermission) DeleteById(id int64) error {
err := u.permission.Check('DeleteById', id)
if err != nil {
return err
}
return u.BookUsecase.DeleteById(id)
}
现在你拥有两个 Usecase,一个给用户使用(判断权限),一个给管理员使用(不判断权限)。
优点
- 关注点分离。也许你会觉得在每个方法中都添加上需要的逻辑并不复杂,封装好之后也就一两行代码,但当你的方法既需要 Log,又需要授权,还要缓存的时候,你就不会这样想了,业务代码本来就很多,再交错上 Tracing,授权的代码就会变得不怎么好看。
- 代码逻辑可以独立文件,可以实现代码自动生成。
QA
Q:代码应该放在 Usecase 还是 Repository ?
在尝试将代码分离到 Usecase 和 Repository 时可能会有一些边界情况不知道如何处理,比如下面的逻辑应该放在 Usecase 还是 Repository?
- 查询 Book 时同时要查询 BookTags,并一起返回
- 删除 Author 时删除他所写的所有 Book
在这里推荐一个方法去帮助区分,即“实现逻辑”放入 Repository,“业务逻辑”放入 Usecase。
什么是实现逻辑?
即一个模块需要几张表,需不需要缓存等实现方案,如上面的问题 1,我们也许使用一张表就实现了,也可能是几张表,为了在今后修改实现方案时不影响到 Usecase 层,我们应该将具体的实现方案封装到 Repository 层。
什么是业务逻辑?
在编写代码的时候需要考虑到后期需求变动,要提前为变动做准备,一般容易变动的需求就是业务逻辑,如上面的问题 2,也许在某天产品经理会修改为:删除 Author 时,将他的所有 Book 移入回收站。业务逻辑应该写在 Usecase 层,这样我们可以在满足开闭原则的前提下修改掉需求,如下:
func (u AuthorUsecase) Delete(ctx context.Context, id int64) (err error) {
...
+++ u.book.MoveToTrash(id)
--- u.book.DeleteByAuthorId(id)
}
实际业务可能更复杂,这个方法也不一定能区分它们,这时可以寻找上级或者同事商量出解决方案(或者随便写在哪里)。
Q:事务逻辑应该放入 Repository 还是 Usecase ?
举例:删除 Author 时删除他所写的所有 Book。在这个例子中,事务逻辑应该放在 Repository 还是 Usecase?
网上有两个观点:
- 放入 Repository,因为 Usecase 不应该关心 Repository 支不支持事务,而放在 Usecase 层开启事务就默认了 Repository 支持事务,当某一个 Repository 由 Mysql 实现切换为 RPC 实现时,代码与预期就会存在偏差。
- 放入 Usecase,因为我们有时候会跨多个 Repository 开启事务,比如上例,需要跨 AuthorRepository 和 BookRepository 开启一个事务。
目前这两个观点还存在争议,意味着两种实现方式都没有致命的缺点。
https://github.com/bxcodec/go-clean-arch/issues/11#issuecomment-528662350
对于跨多个 Repository 开启事务的情况,我们不一定要追求完美的“干净”,我们可以在 AuthorRepository 中开启事务同时去操作两张表。
当然如果想要在 Usecase 层开启事务也不是不可以,我们可以简单的写一个 Transactioner Interface 来减轻 DB 对 Usecase 的入侵。
type Transactioner interface {
Begin(ctx context.Context) (c context.Context, end func(err error) error, err error)
}
func (u AuthorUsecase) Delete(ctx context.Context, id int64) (err error) {
// 开启事务
ctx, end, err := u.transactioner.Begin(ctx)
if err != nil {
return
}
defer func() {
err = end(err)
}()
err = u.book.DeleteByAuthorIdTX(ctx, id)
// if err
err = u.author.DeleteTX(ctx, id)
// if err
}
// 建议 Repository 中的方法以 TX 结尾,显示说明需要支持运行在事务中。
至于如何选择,还请根据团队喜好、实际业务场景而定。
Q:在同一层的封装可以互相引用吗?
不建议,原因如下:
- 不符合向下依赖的原则
- 会导致循环依赖
- 会导致代码的耦合度增加
但有时候好像我们有这样的需求,应该如何解决?
比如在 AuthorUsecase 中需要返回 Book 列表,但 Book 列表的逻辑封装在 BookUsecase 中,看起来必须在 AuthorUsecase 中引用 BookUsecase 才行。
不过还有更好的做法:
- 将 BookUsecase 中处理 Book 列表的逻辑独立出来,放到底层,如 Model 中.不过这个方法不一定适用于所有场景。
- AuthorUsecase 只返回作者信息,BookUsecase 提供一个根据作者信息返回 Book 列表的方法,然后再更上层(如 Service 层)组装它俩的数据。
参考资料
以下参考资料极为重要,记得翻阅它们以保证不会被我一文带偏。
- Uncle Bob - Clean Coder Blog:Uncle Bob 提出的干净架构,具有指导作用,但在自己落地过程中容易偏差。
- Trying Clean Architecture on Golang | Hacker Noon:Github 上 Start 最多的用 Golang 实现,主要参考,基本可以照着抄。
- 在 Golang 上使用整洁架构(Clean Architecture):上篇↑文章的中文译文。
- Applying The Clean Architecture to Go applications • Manuel Kießling:另一种实现,虽然我并不是所有理念都认同,但提出了很多边界问题供思考。